はじめに:その「パースエラー」は、単なるバグではなく経営課題です
LLM(大規模言語モデル)を組み込んだアプリケーションのログに、こんなエラーが頻発しているというケースは珍しくありません。
JSONDecodeError: Expecting value: line 1 column 1 (char 0)
あるいは、AIエージェントがユーザーに対して、本来システム内部で処理すべきJSONデータをそのままチャット画面に「生データ」として吐き出してしまった、という課題も業界内でよく報告されています。
開発フェーズ、特にPoC(概念実証)の段階では、こうしたエラーは「愛嬌」や「調整不足」で済まされることもあります。「プロンプトをもっと厳密にすれば直るはず」と、エンジニアが一生懸命プロンプトエンジニアリングに励む姿も一般的に見られます。
しかし、本番運用を見据えたとき、「出力形式の不安定さ」をプロンプト調整だけで解決しようとするのは、終わりのないモグラ叩きであり、明確なビジネス損失です。
AIはあくまでビジネス課題を解決するための手段にすぎません。AIが指示通りのフォーマットで回答してくれないために発生する「再生成(リトライ)」処理が、どれだけのAPIコスト(トークン課金)を浪費し、どれだけユーザーへのレスポンス(レイテンシ)を悪化させているか、ROI(投資対効果)の観点から定量的に計算することが重要です。
現在、OpenAI APIを取り巻く環境は大きく変化しています。GPT-4o等のレガシーモデルが廃止され、高度な推論能力を持つGPT-5.2や、コーディング特化のGPT-5.3-Codexといった新世代モデルへの移行が進んでいます。モデルの基礎能力が向上し、推論や処理速度が改善されたとしても、システム間連携における出力フォーマットの厳密な制御の重要性は変わりません。むしろ、LangChainなどを用いてより複雑なタスクをAIエージェントに任せるようになるほど、その確実性が強く求められます。
今回は、OpenAI APIの「JSON Mode」や、さらに強力な「Structured Outputs(構造化出力)」といった機能を、単なる便利機能としてではなく、「システム安定性とコスト削減のための必須インフラ」として再定義します。
技術的な実装方法の解説記事は世の中にたくさんあります。ここでは一歩踏み込んで、プロジェクトマネジメントの視点から、経営層やクライアントに「なぜこの実装が必要なのか」を説明するための、ROIとKPI(重要業績評価指標)に基づいた論理的なアプローチを解説します。
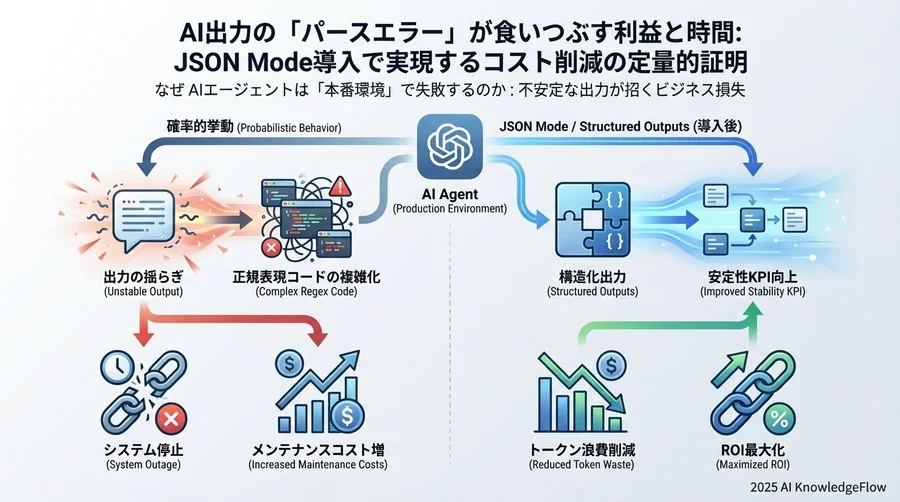
なぜAIエージェントは「本番環境」で失敗するのか:不安定な出力が招くビジネス損失
開発環境では完璧に動いていたAIエージェントが、本番環境にデプロイした途端に不安定になる。これはAI開発でよく見られる課題の一つです。なぜこのようなことが起きるのでしょうか。
開発環境では動くが本番で止まる「確率的挙動」のリスク
従来のシステム開発におけるソフトウェアは「決定的」です。同じ入力には常に同じ出力が返ってきます。しかし、LLMは本質的に「確率的」なシステムです。APIのパラメータである temperature を0に設定しても、完全に決定的な挙動を保証することは難しく、APIのバージョン更新や微細な揺らぎによって、出力内容は変化します。
例えば、ある処理の結果をJSON形式で求めたとします。
{"status": "success", "reason": "ok"}
高い確率でこの形式で返ってくると考えられます。しかし、低い確率で、AIが気を利かせて(あるいは幻覚を見て)こう返すことがあります。
はい、解析が完了しました。結果は以下の通りです。
```json
{"status": "success", "reason": "ok"}
この「前置き」がつくだけで、単純なJSONパーサーはクラッシュします。LangChainなどのフレームワークで複数のプロンプトをチェーンさせている場合、途中のステップでパースエラーが起きるとプロセス全体が停止してしまいます。開発中のテストケースが数十回程度であれば見過ごされがちですが、本番環境で大量のリクエストを処理する場合、運用担当者にとって大きな負担となります。
### エラーハンドリングコードの肥大化と技術的負債
この問題に対処するために、多くの現場で「正規表現(Regex)」による後処理が行われています。「最初の `{` から 最後の `}` までを切り出す」といったロジックです。
しかし、これも万能ではありません。JSONの中にネストされた `{}` があったら? 文字列の中にエスケープされていない改行が含まれていたら? AIがMarkdownのコードブロック(```json ... ```)で囲んで返してきたら?
これら全てのパターンを網羅しようとすると、パース処理のためのコードは複雑化します。従来のシステム開発の知見から言えば、ビジネスロジックと無関係なパース処理の肥大化は深刻な「技術的負債」です。本来、価値創造に使うべき時間を、AIの出力を処理するためのコードのメンテナンスに費やすことになり、リソース配分の最適化とは程遠い状態に陥ります。
## 開発チームが追跡すべき3つの「安定性KPI」
「なんとなく不安定」という定性的な評価では、対策の予算も降りにくいものです。そこで、MLOps(機械学習オペレーション)の観点から、AI機能の品質を測るために推奨される3つの「安定性KPI」を紹介します。これらを継続的にモニタリングすることで、システムの健全性を数値で論理的に把握できるようになります。
### 1. パースエラー率(Parsing Error Rate)
定義: 全リクエスト数のうち、LLMの出力形式が不正で、システム側で解釈できずにエラー(または再生成トリガー)となった割合。
```text
パースエラー率 = (パース失敗回数 / 全LLMリクエスト数) × 100
一般的なプロンプト指示だけの場合、複雑なタスクでは数%程度のエラー率になることもあります。これだけの割合でシステムが止まる、あるいは裏側でリトライしているというのは、Webサービスとしては大きな問題です。目標値は限りなく0%に近づける必要があります。
2. 平均リカバリコスト(Average Recovery Cost)
定義: パースエラーが発生した際に、正しく応答を得るために追加で消費したトークン量(コスト)。
エラーが発生した場合、多くのシステムでは「リトライ(再試行)」を行います。場合によっては「先ほどの出力はJSONとして不正でした。修正してください」というエラーメッセージを含めて再度リクエストを投げます。
これはつまり、「失敗した1回目の出力トークン」+「エラーメッセージの入力トークン」+「修正された2回目の出力トークン」の全てに課金が発生することを意味します。
1回で成功していれば「出力トークン」だけで済んだはずです。つまり、リトライが発生すると、コストは2倍〜3倍になる可能性があります。この「無駄になったコスト」を可視化することが重要です。
3. E2Eレイテンシ変動係数
定義: ユーザーがリクエストを送ってから最終的な応答を得るまでの時間の「ばらつき」。
平均応答時間が3秒だとしても、リトライが発生した時は6秒〜10秒かかっているかもしれません。平均値だけ見ていると、この「時々すごく遅い」現象に気づけません。
リトライは、ユーザー体験(UX)を損ないます。チャットボットで10秒待たされると、ユーザーは「壊れている」と感じて離脱する可能性があります。リトライ発生時のレイテンシ跳ね上がりを監視し、その発生頻度を抑えることが、サービス品質の向上に直結します。
JSON Mode導入によるROI試算:リトライ地獄からの脱却
ここで解決策として登場するのが、OpenAI APIの「JSON Mode」、そしてさらに厳格な出力制御を可能にする「Structured Outputs(構造化出力)」です。
これらは、AIモデルに対して「必ずJSON形式で出力すること」を強制する機能です。特にStructured Outputsは、指定したJSONスキーマに完全に準拠することをAPIレベルで保証するため、開発者にとって極めて強力な武器となります。
複数の公式情報によると、2026年2月にGPT-4oやGPT-4.1といったレガシーモデルが廃止され、より高度な推論能力を持つGPT-5.2(InstantおよびThinking)が新たな主力モデルへと移行しました。このGPT-5.2をベースとした現行のAPI環境においても、JSON ModeやStructured Outputsは標準機能として強力にサポートされています。旧モデルからGPT-5.2へシステムを移行する過渡期であっても、これらの出力制御機能を適切に実装していれば、パースエラーによる手戻りを根本から防ぎ、安定したシステム稼働を維持することが可能です。
では、これらの機能をシステムに組み込むことで、先ほどのKPIやAPIコスト構造(ROI)は具体的にどう変わるのでしょうか。
Before:正規表現抽出によるパース成功率の限界
一般的なデータ抽出プロジェクトにおける従来のシナリオを考えてみましょう。機能導入前は、プロンプト内で「必ずJSONで返して」と強く指示し、受け取ったテキストから正規表現を用いて無理やりJSON部分だけを抽出するアプローチが多く見られました。
- パース成功率: 92%程度(プロンプトの工夫やモデルの機嫌に大きく左右される)
- リトライ発生率: 8%
- APIコスト: 失敗したリトライ分だけ余計に増大
約8%のリクエストでパースエラーによるリトライが発生しており、その分だけ余計なトークンを消費してしまいます。さらに深刻なのは、リトライ処理が応答時間の遅延に直結するという点です。システム連携においてレスポンスの遅れは致命的であり、エンドユーザーからの「処理が遅い」「システムが固まった」という不満につながる大きなリスクを孕んでいます。
After:JSON Mode/Structured Outputsによる改善
ここで Structured Outputs を導入し、厳格なスキーマ定義を行った場合の変化を比較します。ChatGPT環境でこの機能を有効化すると、以下のような劇的な改善が見込めます。
- パース成功率: 100%(APIレベルでのスキーマ準拠保証)
- リトライ発生率: 0%
- APIコスト: 約16%削減(無駄なリトライ排除による直接的な効果)
リトライが完全に消滅することで、無駄なAPIコールがなくなります。さらに注目すべきは、単にエラーが減るだけでなく、「1回あたりのトークン消費量」も最適化されるという副次的効果が期待できる点です。
トークン効率の改善:不要な「前置き」の排除
通常のチャットモードでAPIを呼び出すと、AIは人間らしい自然な振る舞いとして丁寧な言葉を使いたがる傾向があります。
「承知いたしました。ご指定の条件に基づいてデータを抽出しました。以下のJSONをご確認ください...」
人間同士の対話であれば親切な対応ですが、システム間のデータ連携においてはこの前置き部分は完全なノイズであり、かつ無駄な課金対象(出力トークン)です。しかし、JSON ModeやStructured Outputsを有効にすると、AIはこうした不要な挨拶を一切省略し、いきなり { から純粋なデータ出力のみを開始します。
AIの「お喋り」をシステム的に封じ込め、必要なデータだけを最小限のトークンで出力させる。これにより、リトライ削減分と合わせて、トータルでのAPIコスト削減効果は非常に大きくなります。1リクエストあたりの差はわずか数トークンであっても、月間数万リクエストを処理する規模になれば、年間では数十万円単位の利益インパクトをもたらす可能性があります。
つまり、Structured Outputs等の導入は、単なる技術的な好みの問題や開発者の自己満足ではなく、事業の利益率を向上させる明確なコスト削減施策として定義できるのです。
「コード行数」という隠れた指標:開発者体験(DX)へのインパクト
コストやパフォーマンスといった実行時の指標だけでなく、開発チームの生産性(Developer Experience)にも影響があります。
複雑怪奇なパースロジックの廃棄と保守性の向上
実務の現場における事例として、JSON Mode導入に伴いバックエンドのコードをリファクタリングした結果、以下のような変化が報告されています。
- 削除されたコード: 独自の正規表現パース処理、例外発生時の再試行ロジック、部分的なJSON修復ロジックなど、数百行。
- 追加されたコード: Pydanticによるスキーマ定義、数十行。
コード量が大幅に削減されました。しかも、削除されたのは「バグが潜みやすい複雑な処理」で、追加されたのは「宣言的で読みやすい型定義」です。
Pydantic/Zod連携による型安全性の確保
PythonならPydantic、TypeScriptならZodといったライブラリを使って出力スキーマを定義し、それをそのままAPIのパラメータとして渡すことができます。LangChainの出力パーサー(Output Parsers)と組み合わせることで、より堅牢な実装が可能になります。
これにより、アプリケーションコードとAIの出力定義が同期されます。「プロンプトにはフィールドAを出せと書いたけど、受け取る側のコードはフィールドBを待っていた」というような、仕様の食い違い(インピーダンスミスマッチ)を防ぐことができます。
エンジニアは、AIの出力を「信頼できない文字列」としてではなく、「型安全なオブジェクト」として扱えるようになります。これは心理的な負担軽減という意味でも大きなメリットです。
スキーマ変更への対応速度の変化
ビジネス要件が変われば、出力してほしいデータ項目も変わります。従来は、プロンプトの日本語を書き直し、パースロジックを修正し、テストするという手順が必要でした。
Structured Outputsを利用していれば、スキーマ定義(Pydanticのクラスなど)にフィールドを1行追加するだけで済むと考えられます。変更にかかるリードタイムが短縮され、ビジネスの変化に素早く追随できるAIエージェントが実現します。
測定と監視の落とし穴:JSON Modeでも防げないエラーとは
ここまでJSON Modeの有効性を評価してきましたが、最後に釘を刺しておかなければなりません。この機能は決して「銀の弾丸」ではありません。
「形式は正しいが中身が幻覚(ハルシネーション)」の検知難易度
JSON ModeやStructured Outputsが保証するのは、あくまで「構文(Syntax)の正しさ」と「スキーマ(型)への準拠」です。「内容(Semantics)の正しさ」までは保証してくれません。
例えば、「日本の首都は?」という問いに対し、以下のようなJSONが返ってくる可能性があります。
{"capital": "大阪"}
これはJSONとしては完璧に正しいですし、スキーマが {"capital": string} であれば型も合っています。しかし、事実としては間違っています。
形式エラーが激減すると、開発者は安心してしまい、出力内容の検証を怠りがちになります。形式が整っているからこそ、誤った情報がシステムに紛れ込むリスクが高まるとも言えます。
検証レイヤー(Validation Layer)の必要性
したがって、パース処理のコードが不要になった分、浮いたリソースを「意味的な検証(Validation)」に回すべきです。
- 数値データなら、あり得ない範囲の値になっていないか(年齢が200歳など)。
- 参照IDなら、データベースに実在するか。
- テキストなら、不適切な表現が含まれていないか。
これらをチェックする「ガードレール」や「バリデーションレイヤー」を設けることは、実用的なAIエージェント開発において極めて重要です。RAG(検索拡張生成)を組み合わせている場合でも、抽出された情報がソースドキュメントに裏付けられているかを検証するプロセスが不可欠です。
スキーマ複雑化によるモデルの理解度低下
また、あまりに複雑で深いネスト構造を持つJSONスキーマを定義すると、モデルがその構造を理解しきれず、回答の精度自体が落ちることがあります。
現在、APIの利用環境は急速に進化しています。OpenAIのAPIでは、GPT-4o等のレガシーモデルが廃止され、100万トークン級のコンテキストや高度な推論能力を備えたGPT-5.2が新たな標準モデルへ移行しています。また、開発タスクに最適化されたGPT-5.3-Codexのような特化型モデルも登場しています。
このようにモデルの基礎能力は向上していますが、処理速度やコスト効率を重視して軽量モデルを利用する場合や、モデルの推論能力を超える過度な構造化を要求する場合は、依然として注意が必要です。「構造化できるから」といって何でもかんでも詰め込むのではなく、AIが理解しやすいシンプルな構造を設計する能力も、これからのプロジェクトマネージャーやエンジニアには求められます。
まとめ:信頼されるAIエージェントへの第一歩
今回は、JSON ModeおよびStructured Outputsの導入を、コストと品質の観点から解説しました。
要点を振り返ります。
- 不安定な出力はコスト: パースエラーによるリトライは、APIコストを増加させ、ユーザー体験を悪化させる。
- 構造化出力でROI改善: JSON Mode等の導入により、リトライを減らし、トークン効率を高めることで、コスト削減が可能。
- 開発者体験の向上: 複雑なパースコードを減らし、型定義中心の開発に移行することで、保守性と変更容易性が高まる。
- 検証の重要性: 形式が正しくても内容は疑うこと。意味的なバリデーション体制は必須。
「AIだから多少の間違いは仕方ない」という言い訳は、もはや通用しなくなってきています。システムとして組み込む以上、確実性や安定性を高める努力はエンジニアリングの責務です。
もし、現在のAI開発プロジェクトで「エラー率が高い」「APIコストが見積もりを超過している」といった課題に直面している場合は、ぜひ一度、出力制御のアーキテクチャを見直してみてください。
コメント