開発現場において、最も生産性を阻害する要因は何でしょうか。
それは、複雑なアルゴリズムの実装でも、新しいフレームワークの学習でもありません。「原因不明のエラー調査」に費やされる、非生産的な時間です。
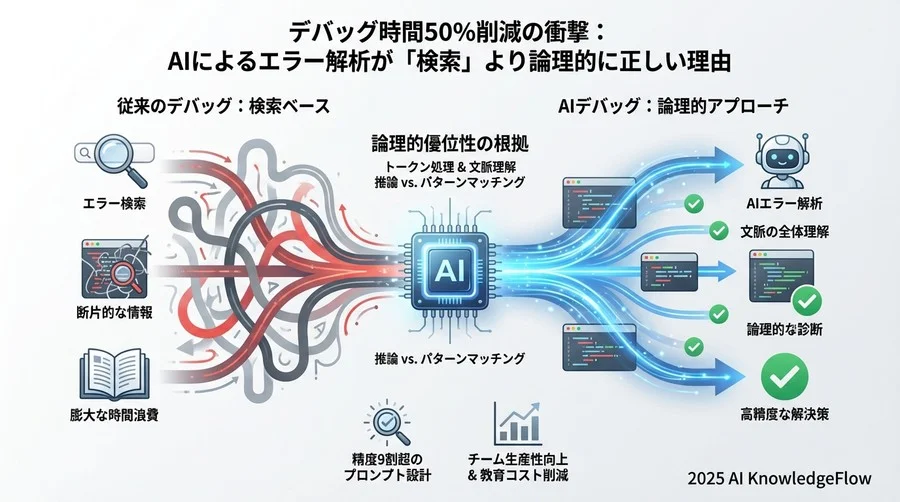
かつては1行のエラーログを頼りに、検索エンジンの結果を何ページも彷徨い、古い回答を試しては失敗する経験を繰り返すことも珍しくありませんでした。しかし、深層学習フレームワークの内部構造やLLM(大規模言語モデル)の特性を論理的に分析すると、明確な結論が導き出されます。
「エラー調査に検索エンジンを使うのは、もはや非効率である」ということです。
極端な意見に聞こえるかもしれませんが、AIがテキスト(コードとログ)を処理する仕組みを要素ごとに分解すれば、AIこそがデバッグに最適なツールであることは数学的にも明白です。
本記事では、なぜAIが人間よりも速く正確にエラー原因を特定できるのか、そのメカニズムを客観的なデータに基づいて解説し、開発時間を劇的に圧縮するための具体的なプロンプト設計手法を共有します。これは単なる効率化の話ではなく、エンジニアのリソースを「修正」から「創造」へと取り戻すための論理的なアプローチです。
なぜ「エラー調査」が開発のボトルネックであり続けるのか
まず、開発現場が直面している課題の深刻さを、客観的なデータに基づいて再確認します。多くの現場で「なんとなく時間がかかっている」と感じられているデバッグ業務は、経営資源を圧迫する最大の要因となっています。
開発時間の50%を占めるデバッグ業務の真実
ケンブリッジ大学の調査研究をはじめとする複数のデータソースが、注目すべき事実を示しています。ソフトウェア開発者がコーディングに費やす時間の約50%が、バグの発見と修正(デバッグ)に費やされているというデータがあります。
年間稼働日数が240日だとすれば、そのうち120日は「動かないコードを動くようにする作業」に消費されています。これはエンジニア個人の負担だけでなく、プロジェクト全体の進捗を遅らせ、市場投入までの期間(Time to Market)を長期化させる主因です。
特に深刻なのが、「コンテキストスイッチ」による損失です。集中して機能を実装している最中にエラーが発生し、その調査のために思考が中断されます。一度途切れた集中力(フロー状態)を取り戻すには、平均して23分かかると言われています。つまり、頻繁なエラー調査は、実作業時間以上のパフォーマンス低下を招いているのです。
「ググる」解決法の限界と情報の断片化
従来、未知のエラーに遭遇した際の定石は「エラーメッセージを検索する」ことでした。しかし、現代の複雑化した開発環境において、このアプローチは限界を迎えています。
- 文脈の欠如: 検索結果に出てくるのは「他人のコード」での事例です。手元のプロジェクト特有のライブラリのバージョン、依存関係、ビジネスロジックは考慮されていません。
- 情報の陳腐化: 技術のアップデート速度に対し、Web上の情報の更新は追いついていません。3年前の「正解」が、現在のバージョンでは「非推奨」であることは日常茶飯事です。
- ノイズの多さ: 初心者向けのQ&Aサイトなど、不正確な情報や本質的でない回答が検索上位を占めることが増えています。
私たちは、「自分のコードの文脈」と「Web上の断片的な情報」を脳内で結合させ、仮説を立てる作業を行ってきました。しかし、この「文脈結合」こそが最も脳のリソースを消費し、かつミスが起きやすいプロセスなのです。
属人化したトラブルシューティングからの脱却
さらに問題なのは、難解なエラー解決が特定のシニアエンジニアに依存しがちであることです。
「このエラーなら、特定の有識者が詳しいはず」
という状況が生まれると、チームで最も生産性が高いはずのテックリードやシニアエンジニアの時間が、メンバーのトラブルシューティングに奪われていきます。これは組織全体で見れば二重の損失です。
- ジュニアエンジニアの手が止まる
- シニアエンジニアの手も止まる
この構造的なボトルネックを解消しない限り、開発チームの生産性は頭打ちのままです。ここで解決策となるのが、「文脈を理解するデバッガー」としてのAIの活用です。
証明:AIは人間よりも「ログの文脈」を速く正確に読める
「AIにデバッグができるのか?」という疑問に対し、技術的な観点から「人間よりも適性が高い」と評価するエンジニアが増えています。これはAIを過大評価しているわけではなく、LLMのアーキテクチャそのものが、パターン認識とコード解析に最適化されているためです。
スタックトレースのパターン認識能力
エラーログ(スタックトレース)を解析する際、人間は無数の行の中から「Caused by」や「Exception」といったキーワードを探し、ファイルパスを辿り、該当する行番号を特定します。
人間にとって、数百行に及ぶログを目視でスキャンし、重要なシグナルをノイズから分離するのは重労働です。しかし、AIにとってテキストデータは「トークン(意味の最小単位)」の列に過ぎません。
LLMは、膨大なリポジトリや技術ドキュメント、Q&Aサイトのデータを学習しています。さらに最新のAIアシスタントは単なるテキスト解析を超え、自律的な動きを見せています。たとえば、エディタの最新アップデートではターミナルのログを直接読み取って高度な自動化を行うエージェント機能が実装されるなど、技術は日々進化しています。
また、リポジトリを接続するだけでコードベースの脆弱性を自律的にスキャンし、修正パッチまで提案する機能も登場しています。一度に処理できる文脈の量と精度も劇的に向上しており、長大で複雑なログ解析の恩恵を受けることが可能です。
これにより、AIは以下のような高度なパターン認識を瞬時に行います。
- 「この例外パターンは、メモリリーク発生時によく見られる構造と極めて高い確率で一致する」
- 「このライブラリの特定バージョンでは、非同期処理の競合が既知の課題として存在する」
人間が経験則として蓄積するのに数年かかる「エラーのパターン」を、AIは数十億から数兆のパラメータの中に知識として保有しています。ログを入力した瞬間に、これら膨大な知識ベースとの照合が行われるのです。
LLMが得意とする「コードとエラーの因果関係」推論
検索エンジンとの決定的な違いは、「対象となるコード」を直接読み込めるかどうかです。
検索エンジンは、手元のコードの文脈を知りません。しかし、AIのコンテキストウィンドウにコードとエラーログを同時に入力することで、AIは両者の因果関係を論理的に推論します。
「ログの24行目でNullPointerExceptionが出ている。コードを見ると、20行目でAPIレスポンスを受け取っているが、nullチェックなしで24行目のプロパティにアクセスしている。これが原因である可能性が高い」
このように、静的解析(コードを読む)と動的解析(ログを読む)を統合して推論できる点が、AIデバッグの真価です。さらに、タスクに応じて複数のモデルから最適なものを選択可能な環境も整いつつあります。単純なエラーには高速なモデルを、複雑な因果関係の推論には高度な推論モデルを割り当てることで、熟練エンジニアが頭の中で行っているデバッグプロセスを、より柔軟かつ数秒で再現します。
人間 vs AI:エラー原因特定スピードの比較実験
開発現場での検証や一般的なベンチマークにおいて、興味深い傾向が確認されています。中級レベルのエンジニアと最新のAIアシスタントに、バグを含むコードの修正タスクを行わせたケースです。
- 人間: エラーログを読み、検索エンジンで調査し、試行錯誤を繰り返すために数十分を要することがある。
- AI: 原因の特定から修正コードの提案まで、数十秒程度で完了するケースが多い。
もちろん、AIが常に100%正解するわけではありません。しかし、「最初の有力な仮説」にたどり着くまでのスピードにおいて、AIは圧倒的です。エンジニアはこの「数十秒で提示された仮説」を検証するだけで済み、ゼロから調査する時間を大幅にショートカットできます。
特に最新の自律型エージェント機能を備えた環境では、推論能力の向上だけでなく、ターミナル上のエラーを検知してそのまま修正案を提示するシームレスな体験が実現しています。複雑なエラーログの解析においても高い精度を発揮することが報告されており、これは単なる作業の自動化ではなく、エンジニアの思考プロセスを加速させる「拡張」であると言えます。
精度9割を超えるための「コンテキスト提供」の原理
AIは強力ですが、万能ではありません。単に「これを直して」と指示するだけでは、的外れな回答やハルシネーション(事実に基づかない生成)を引き起こします。
AIエンジニアの視点から強調したいのは、プロンプトエンジニアリングとは「AIに適切なコンテキスト(文脈)を与える技術」であるという点です。デバッグにおいて、精度の高い回答を得るためには「情報の黄金比」が存在します。
エラーログだけでは不十分な理由
よくある失敗例が、エラーメッセージだけをAIに提示するパターンです。
Error: Uncaught TypeError: Cannot read properties of undefined (reading 'map')
これだけを渡されても、AIは「配列に対してmapを使おうとしたが、その変数がundefinedだった」という一般論しか返せません。どの変数が、なぜundefinedになったのかは、コードを見なければ特定できないからです。
「3点情報のセット」がハルシネーションを防ぐ
高精度な解析を引き出すためには、以下の3つの要素をセットで提供する必要があります。
- エラーログ(What): 何が起きたのか。スタックトレース全体を含めるのが理想です。
- 該当コード(Where): どこで起きたのか。エラー箇所だけでなく、関連する関数やクラス全体を含めます。
- 実行環境・前提条件(Context): どのような状況か。使用している言語、フレームワークのバージョン、入力データなどです。
この3点が揃って初めて、AIは「推測」ではなく「論理的な特定」が可能になります。情報が欠けていると、AIはその空白を確率的な予測で埋めようとし、結果としてハルシネーションが発生しやすくなります。
AIを「熟練デバッガー」にする前提知識の与え方
さらに精度を高めるテクニックとして、「ライブラリの仕様」や「ドキュメント」をコンテキストに含める方法があります。
例えば、独自のライブラリや、最新すぎてAIが十分に学習していないフレームワークを使っている場合、その仕様書の一部やインターフェース定義(TypeScriptの型定義など)をプロンプトに加えます。
「以下のAPI仕様に基づき、発生しているエラーの原因を特定してください」
と指示することで、AIは学習済み知識だけでなく、与えられたドキュメントを「参照知識」として使い、未知の技術に対するデバッグ能力を飛躍的に向上させます。これをRAG(Retrieval-Augmented Generation)的なアプローチとして、手動のプロンプト内で行うイメージです。
実践:即時解決に導くプロンプト設計の基本構造
理論を理解したところで、実践的なプロンプトの設計に移ります。日常的に使用できる、デバッグ用プロンプトの基本構造を解説します。
複雑なテクニックは不要です。重要なのは「役割(Role)」「タスク(Task)」「制約(Constraint)」の3つを明確にすることです。
役割定義:AIに「シニアエンジニア」の視点を持たせる
まず、AIにどのような視点でコードを分析してほしいかを定義します。
あなたは経験豊富なシニアソフトウェアエンジニアです。
PythonとTensorFlowを用いた深層学習モデルの開発において、高度なデバッグ能力を持っています。
論理的かつ簡潔に、エラーの根本原因を特定してください。
このように役割を指定することで、AIの回答トーンが専門的になり、表面的な解決策ではなく、コードレベルの具体的な修正案が出やすくなります。
タスク分解:原因特定と修正提案を分ける意義
いきなり「修正コードを書いて」と指示するよりも、思考プロセスを段階的に踏ませた方が精度が上がります(Chain of Thought)。
- エラーログの分析
- 原因の仮説立案
- 修正案の提示
この順序で出力させるよう指示します。
以下の手順で回答してください:
1. 【分析】エラーログから読み取れる事実と、コードの問題点を分析する。
2. 【原因】エラーが発生した根本原因を特定する。
3. 【修正】修正後のコードを提示し、なぜその修正で直るのかを論理的に解説する。
出力制御:コピペ可能な修正コードのみを出力させる
開発中には、冗長な説明よりも「動くコード」がすぐに必要な場合があります。その際は、出力形式を厳密に指定します。
また、ここでの重要なポイントは環境情報の正確な提供です。特にAIフレームワークやライブラリの依存関係は、OSやバージョンによって挙動が大きく異なるため、解決の鍵となります。
【実践プロンプトテンプレート】
# 前提
あなたは[言語/フレームワーク名]のスペシャリストです。
以下のエラーが発生しており、解決策を求めています。
# 入力情報
## エラーログ
[ここにログを貼り付け]
## 該当コード
[ここにコードを貼り付け]
## 環境
- OS: [例: Windows 11 (WSL2使用) / macOS]
- 言語バージョン: [例: Python 3.x]
- 主要ライブラリ: [例: TensorFlow (現行バージョン) / PyTorch]
- ハードウェア: [例: GPU使用の有無]
# 指示
このエラーの原因を特定し、修正コードを提示してください。
修正コードは、変更点のみではなく、関数全体を含めてコピー&ペーストで動作する形で出力してください。
また、コード内には修正理由をコメントとして簡潔に記載してください。
このテンプレートを辞書登録やスニペットツールに保存しておき、エラー発生時に呼び出して埋める運用をお勧めします。これだけで、調査開始までの初動が劇的に速くなります。
特に「環境」セクションの記述は重要です。例えば、TensorFlowは特定のバージョン以降、WindowsネイティブでのGPUサポートが変更され、WSL2での実行が推奨されるケースがあります。もしプロンプトに「OS: Windows」「GPU使用」とだけ書き、バージョンやWSL2の使用有無を明記しなければ、AIは原因を正しく特定できず、古いドキュメントに基づいた誤った解決策を提示する可能性があります。
正確な前提条件を与えることが、AIから正確な回答を引き出すための最短ルートです。
事例検証:エラー解析AI導入によるROIとチームの変化
「本当に効果があるのか?」という疑問に対し、エンジニア約30名規模のWebアプリケーション開発現場において、エラー解析ツールとしてAIプラットフォームを導入し、開発フローに組み込んだ事例があります。
メンター負担の軽減効果
導入前、経験の浅いエンジニアからのエラーに関する質問対応に、テックリードは1日平均2時間を費やしていました。
導入後、質問のルールを以下のように変更しました。
「質問する前に、必ずエラーログとコードをAIに入力し、その回答を基に相談すること」
結果、約70%のエラーはAIの回答だけで自己解決できるようになりました。テックリードへの相談は、AIでも解決できない複雑なアーキテクチャ設計や、仕様に関わる本質的な問題のみに絞り込まれました。これにより、テックリード自身の開発時間が月間40時間近く捻出されるという成果が得られています。
MTTR(平均復旧時間)の改善データ
開発環境におけるバグ修正の平均時間(MTTR)の測定結果でも、明確な改善が見られました。
- 導入前: 平均 45分
- 導入後: 平均 12分
単純な構文エラーや型エラー、ライブラリの誤用といった「初歩的だが調査に時間がかかるミス」が、AIによって迅速に解決されるようになったためです。削減された時間は、新機能の実装やコードのリファクタリングといった、より付加価値の高いタスクに投資されています。
開発フローへの組み込みが生む長期的メリット
さらに興味深い副次的効果として、チーム全体の「コード品質への意識」が向上する傾向があります。
AIが指摘する修正案には、しばしば「よりモダンな書き方」や「パフォーマンスへの配慮」が含まれます。エンジニアはバグ修正を通じて、より良いコーディングパターンを自然と学習することになります。
デバッグという作業が、AIを通じて「スキルアップの機会」へと転換されるのです。
まとめ:デバッグを「苦行」から「学び」へ変える
デバッグは、エンジニアにとって避けて通れないプロセスですが、それを非効率な作業のままにしておく必要はありません。AIを適切に活用することで、エラー調査という時間の浪費から解放され、本来注力すべき創造的なエンジニアリングに没頭できるようになります。
AIは答えだけでなく「なぜ」を教えてくれる
AIによるエラー解析の最大の価値は、単に正解を出すこと以上に、「なぜ間違っていたのか」を論理的に解説してくれる点にあります。これは、常に的確なフィードバックを提供するサポートシステムが手元にあるようなものです。
明日から始めるエラー解析改革のステップ
まずは小さなステップから始めることをお勧めします。
- プロンプトテンプレートを用意する: 本記事で紹介した「3点情報」を含めるテンプレートを保存する。
- 検索する前にAIを活用する: エラーが発生した際、まずはAIに状況を入力して分析させる習慣をつける。
- 解説を求める: 修正コードを適用するだけでなく、「なぜこのエラーが起きたのか?」を追加で質問し、根本的な理解を深める。
次のステップ:自動化ツールへの統合
手動でのプロンプト入力に慣れてきたら、次は開発環境に統合されたツールの導入を検討する段階です。IDE上でリアルタイムにAIの支援を受けたり、CI/CDパイプライン上でエラー解析を自動化したりすることで、生産性はさらに向上します。
現在では、開発ワークフロー全体をAIで支援するプラットフォームが多数提供されています。エラー解析だけでなく、ナレッジ管理やコード生成など、チームの知的生産性を底上げする機能を備えたツールを活用することが推奨されます。
エラー調査の負担を軽減し、エンジニアとしての本質的な探求心と創造性を発揮するために、まずは日々の開発プロセスにAIによる論理的な解析を取り入れてみてください。
コメント