AI導入の現場で、「とりあえずスモールスタートだから、APIでいいよね?」という会話がよく交わされます。確かに、初期投資が少ないAPI利用は魅力的です。しかし、サービスが軌道に乗り、ユーザー数が急増した結果、想定外の請求額に直面する「クラウド破産」に近い事例が後を絶ちません。
一方で、セキュリティ要件の厳しいプロジェクトでは、「データは外に出せないからローカル構築一択」と判断されることも多いですが、そこにもGPUサーバーの調達コストや、維持管理という見えにくい「固定費」の罠が潜んでいます。
特に、日本語性能に優れた国産LLM(ELYZA, CyberAgent, Rinnaなど)を採用する場合、海外製モデルとは異なるコスト構造やトークン効率を考慮しなければなりません。「APIの方が安い」は本当なのか? それとも「ローカル構築」が長期的には賢い選択なのか?
本記事では、プロジェクトの意思決定をサポートするため、「自社の数値を入力するだけで、最適な運用形態をAIに判定させる」プロンプトテンプレート集を紹介します。AIを活用し、論理的に未来のコスト構造をシミュレーションする手法を解説します。
1. このテンプレート集の目的と活用法
なぜ、わざわざAIを使ってコスト試算をする必要があるのでしょうか? それは、LLMの運用コストが「単純な掛け算」では算出できないほど複雑だからです。
「なんとなくAPI」で失敗する理由
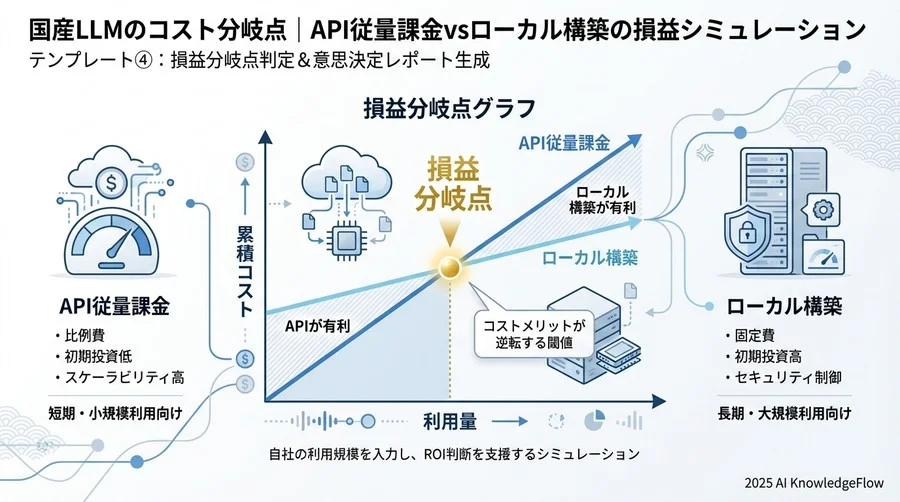
API利用料は「従量課金(変動費)」です。利用者が少ないうちは安価ですが、ビジネスが成功してアクセスが増えれば増えるほど、コストは青天井に伸びていきます。逆に、ローカル環境(オンプレミスやプライベートクラウド)での運用は、初期投資やサーバー維持費といった「固定費」が重くのしかかりますが、ある一定の利用量を超えれば、1処理あたりのコストは劇的に下がります。
この「変動費」と「固定費」の逆転ポイント(損益分岐点)を見極めずにスタートするのは、羅針盤なしで航海に出るようなものです。
変動費(API)と固定費(ローカル)の構造的違い
- API利用(変動費型):
- メリット:初期費用ほぼゼロ、管理工数少、最新モデルへの切り替え容易
- デメリット:データ量に比例してコスト増、レート制限のリスク、データプライバシーの懸念
- ローカル構築(固定費型):
- メリット:データ量が増えてもコスト一定、セキュリティ強固、カスタマイズ自由
- デメリット:GPU調達コスト大、インフラ保守の人件費、ハードウェアの陳腐化リスク
本記事のゴール:自社に最適な運用モデルの即時判定
これから紹介する4つのプロンプトテンプレートを使えば、以下のことが可能になります。
- 曖昧な「AI活用」を具体的な「トークン消費量」に変換する
- API利用時の将来的なコスト増大リスクを可視化する
- ローカル運用にかかる「隠れたコスト」を含めた総保有コスト(TCO)を算出する
- 両者を比較し、「月間〇〇万トークン以上ならローカルがお得」という具体的な閾値を導き出す
経営層への稟議書に活用できる、客観的かつ論理的な根拠を構築することが可能です。
2. プロンプト設計の基本:コスト試算の変数を定義する
AIに正確な計算をさせるためには、適切な「変数」を定義する必要があります。入力データが正確でなければ、精度の高い結果は得られません。
LLMコストを左右する3つの主要変数
コスト試算において、以下の3つの数字が鍵を握ります。
- 入力トークン数(Input Tokens): ユーザーがAIに投げかける質問や、参照させるドキュメントの量。
- 出力トークン数(Output Tokens): AIが生成する回答の量。一般的に、出力トークンの方が単価が高い傾向にあります。
- リクエスト頻度(RPM/RPH): 1分間または1時間あたりのリクエスト数。これによって必要なGPUスペックやAPIのレート制限が決まります。
国産LLM特有のトークン計算事情
ここで注意が必要なのは、「日本語のトークン効率」です。海外製モデル(Llama 2など)のトークナイザーは日本語を細切れにしがちで、トークン数が膨らむ傾向があります。一方、国産LLM(例:ELYZA-japanese-Llama-2など)は日本語に最適化されており、同じ文章でもトークン数が少なく済む場合があります。
この「トークン効率」の違いも、コストに直結する重要なファクターです。
試算精度を高めるための前提条件フレームワーク
プロンプトに入力する際は、以下の情報を整理しておくとスムーズです。
- 対象業務: 社内ヘルプデスク、顧客対応チャットボット、議事録要約など
- 利用人数: 月間アクティブユーザー数
- 平均利用回数: 1人あたりの1日平均利用回数
- 平均文字数: 1回あたりの入力・出力文字数(日本語)
これらの情報を整理した上で、実際のプロンプトを活用したシミュレーション手順を解説します。
3. テンプレート①:利用規模・要件定義アシスタント
まずは、対象となる業務シナリオから「月間にどれくらいのトークンを消費するか」を見積もります。この工程は複雑になりがちですが、AIを活用することで効率的に算出できます。
以下のプロンプトをコピーして、[ ]の部分を自社の状況に合わせて書き換え、ChatGPTやClaudeなどのLLMに入力してください。
# 命令書: 国産LLM利用規模・トークン消費量試算
あなたはAI導入コンサルタントです。以下の[前提条件]に基づき、月間のトークン消費量と必要なシステムスループットを試算してください。
## 前提条件

- 対象業務: [社内ナレッジ検索および日報作成支援]
- 利用対象者数: [全社員 500名]
- 稼働日数: [20日/月]
- 1人あたり平均利用回数: [1日 5回]
- 1回あたりの平均入力文字数(日本語): [約400文字 (検索クエリ+参照ドキュメント)]
- 1回あたりの平均出力文字数(日本語): [約600文字 (回答+要約)]
- ピーク時の同時アクセス集中率: [全社員の20%が9:00-10:00に集中すると想定]
## 試算ルール
1. 日本語1文字あたりのトークン換算は、国産LLM(日本語最適化トークナイザー)を想定し、「1文字 = 0.8トークン」として計算すること。
2. 月間総入力トークン数、月間総出力トークン数を算出すること。
3. ピーク時に必要な毎分トークン処理量(TPM)を推計すること。
## 出力形式
| 項目 | 試算値 |
| --- | --- |
| 月間総リクエスト数 | |
| 月間総入力トークン | |
| 月間総出力トークン | |
| 合計月間トークン数 | |
| ピーク時必要TPM | |
## 考察
この規模感におけるインフラへの負荷レベルについて、定性的なコメントも追記してください。
このプロンプトのポイント
- トークン換算レート: 日本語に強い国産モデルを想定し、少し有利なレート(0.8トークン/文字)を設定しています。厳しめに見積もるなら「1文字=1.2トークン」程度に変更しても良いでしょう。
- ピークタイムの考慮: ローカル構築の場合、平均値ではなく「最大瞬間風速」に合わせてGPUを用意する必要があるため、この項目が重要になります。
4. テンプレート②:API利用時のコスト予測シミュレーター
利用量がわかったら、次はAPIを利用した場合のコスト計算です。ここでは、架空または実在する国産LLMのAPI価格を適用してシミュレーションします。
# 命令書: 国産LLM API利用コスト予測シミュレーション
テンプレート①で算出した[合計月間トークン数: 〇〇万トークン](入力:出力 = 4:6 と仮定)に基づき、API利用時のコストを試算してください。
## 価格モデル(例: 一般的な国産LLM API相場)
- 入力トークン単価: [1.5円 / 1,000トークン]
- 出力トークン単価: [2.5円 / 1,000トークン]
- 固定基本料金: [0円]
## シミュレーション条件
1. 現状維持シナリオ: 現在の利用量が1年間続いた場合
2. 成長シナリオ: 利用量が毎月[5%]ずつ増加した場合の1年後、3年後の月額コスト
## 出力形式
### 1. 月額・年額コスト試算(現状維持)
- 月額コスト: [ ] 円
- 年間コスト: [ ] 円
### 2. 将来予測(成長シナリオ: 月次+5%)
- 1年後の月額コスト: [ ] 円
- 3年後の月額コスト: [ ] 円
- 3年間の累積コスト: [ ] 円
## リスク分析
API利用におけるコスト変動リスク(為替、価格改定、予期せぬ利用増など)について簡潔に警告してください。
為替リスクや改定リスクの織り込み
国産LLMであっても、バックエンドのインフラが海外クラウド(AWS, Azure, GCP)の場合、為替の影響で価格改定が起こる可能性があります。「円安リスク」を考慮に入れるかどうかも、経営判断の一つです。
5. テンプレート③:ローカル環境構築・運用コスト試算
ローカル構築(オンプレミスやプライベートクラウドのIaaS利用)の試算においては、初期費用だけでなく、運用費(Opex)を漏れなく計上することが重要です。
# 命令書: 国産LLM ローカル構築・運用TCO試算
以下の要件を満たすローカルLLM環境を構築する場合の、3年間の総保有コスト(TCO)を試算してください。
## モデル要件
- モデルサイズ: [70Bクラス (例: ELYZA-japanese-Llama-2-70b)]
- 量子化: [4bit量子化を使用 (VRAM削減のため)]
- 必要VRAM目安: [48GB x 2枚 = 96GB]
## コストパラメータ
1. 初期費用 (Capex)
- GPUサーバー調達費: [300万円 (A6000 Ada x2 搭載ワークステーション想定)]
- セットアップ人件費: [エンジニア2人月 = 200万円]
2. 運用費用 (Opex)
- 電気代・データセンター費用: [月額 5万円]
- 保守運用人件費(モデル更新、障害対応): [月額 0.2人月 = 20万円]
- ハードウェア保守契約: [年額 30万円]
## 出力形式
### 1. コスト内訳
- 初期投資合計: [ ] 円
- 年間運用費合計: [ ] 円
### 2. 3年間TCO
- 1年目合計(初期+運用): [ ] 円
- 2年目合計(運用のみ): [ ] 円
- 3年目合計(運用のみ): [ ] 円
- 3年間総額: [ ] 円
## 比較視点
この構成での「月間最大処理可能トークン数」を概算し、API利用と比較した際のメリット(使い放題である点など)を提示してください。
必要GPUスペックの選定とハードウェア償却計算
モデルサイズ(7B, 13B, 70B)によって必要なGPUメモリ(VRAM)は決まります。70Bクラスを快適に動かすには、コンシューマー向けGPUでは厳しく、業務用GPUが必要になることが多いです。このプロンプトでは、そうしたハードウェアの現実的な価格感を反映させることが重要です。
6. テンプレート④:損益分岐点判定&意思決定レポート生成
最後に、これまでの試算結果を統合し、APIとローカルのどちらがコストメリットを持つか、その分岐点を判定します。これが稟議書における「結論」の根拠となります。
# 命令書: API vs ローカル 損益分岐点分析レポート
これまでの試算に基づき、API利用とローカル構築の損益分岐点を特定し、経営層向けの推奨レポートを作成してください。
## 入力データ
- API利用時の月額コスト(現状): [テンプレート②の結果を入力]
- ローカル構築の3年間TCO: [テンプレート③の結果を入力]
- ローカル構築の月額換算コスト(3年償却): [TCO ÷ 36ヶ月]
## 分析指示
1. 損益分岐点(Break-even Point)の算出
- 月間トークン量が何万トークンを超えた時点で、ローカル構築の方が安くなるかを計算してください。
- 期間軸での分岐点(運用開始から何ヶ月目でローカル構築の初期投資を回収できるか)を計算してください。
2. 総合評価マトリクス
- コスト、セキュリティ、カスタマイズ性、運用手間の4軸で両者を比較評価(◎、○、△、×)してください。
3. エグゼクティブサマリー(推奨案)
- [現状の利用規模]においては、どちらのプランを推奨するか。
- どのような条件変化(例:利用量2倍増、セキュリティ規制強化)があれば、推奨が変わるか。
## 出力トーン
客観的かつ論理的で、決裁者が判断しやすいビジネス文書形式。
定量的・定性的評価のマトリクス生成
システム導入の意思決定はコストのみでは完結しません。ローカル環境の運用にはエンジニアのリソースが不可欠であり、API利用はセキュリティポリシーによる制限を受ける場合があります。このプロンプトは、そうした定性的な要素も含めた総合的な評価を導き出します。
7. よくある試算ミスと失敗パターン
最後に、実務の現場で発生しやすい「計算違い」や「見落とし」について解説します。シミュレーションを行う際は、以下の点に注意が必要です。
「初期費用」しか見ていない落とし穴
「GPUサーバーを導入すれば、その後の費用はかからない」というのは誤解です。電力コストに加え、AIモデルの陳腐化という事実を考慮する必要があります。短期間で新しいSOTA(State of the Art)モデルが登場するため、モデルの入れ替え、検証、プロンプト調整にかかる「エンジニアの工数」が、最大のコスト要因となる傾向があります。
プロンプトエンジニアリング工数の計上漏れ
国産LLMは、GPT-4などの超巨大モデルに比べて、指示の理解力に癖がある場合があります。期待通りの出力を得るためのプロンプト調整(プロンプトエンジニアリング)や、場合によってはファインチューニング(追加学習)が必要になり、そのコストがAPI利用料を上回ることもあります。
モデルの陳腐化サイクルを無視した選定
「3年償却」で計算した場合でも、3年後にはそのGPUスペックで最新モデルが稼働しない可能性があります。AI技術の進化スピードはハードウェアの償却サイクルを上回るため、ローカル構築の際は、VRAM容量などに余裕を持たせたスペック選定が推奨されます。
まとめ:数字を味方につけて、確信のある投資を
本記事では、4つのプロンプトテンプレートを活用し、APIとローカル運用のコスト比較を論理的に行う手法を解説しました。
- テンプレート①で、曖昧な「AI活用」を「トークン量」という数値に変換する。
- テンプレート②・③で、変動費と固定費それぞれの未来を予測する。
- テンプレート④で、自社にとっての損益分岐点を明確にする。
これらを実践することで、「月間利用量が〇〇を超え、かつセキュリティ要件を鑑みると、ローカル構築が〇ヶ月目でペイする」といった、データに基づく具体的な戦略の立案が可能になります。
コストは重要な指標ですが、それが唯一の判断基準ではありません。実際に国産LLMを導入し、業務効率化を実現した事例において、どのような基準でAPIやローカル環境が選択されたのかを分析することは、システム設計の大きなヒントとなります。
次のステップとして、類似の課題を持つ組織がどのような決断を下し、成果を上げているのか、具体的な導入事例を参照することをおすすめします。客観的なデータと実例を掛け合わせることで、シミュレーション結果に基づく意思決定の精度がより一層高まるはずです。
コメント